
Cloud cost reduction is often treated as a finance exercise. In reality, it is an engineering, product, and operating discipline.
The fastest way to reduce cloud spend is usually obvious: shut things down, downgrade infrastructure, delay upgrades, reduce redundancy, or enforce aggressive usage limits. The problem is that these actions can quietly damage performance, resilience, developer velocity, or customer experience.
The better question is not, “How do we spend less on cloud?”
It is, “How do we remove waste while preserving the performance characteristics the business actually needs?”
That distinction matters. Many organizations are not overspending because the cloud is inherently expensive. They are overspending because cloud usage has become disconnected from product priorities, architectural intent, and operational accountability.
Why Cloud Cost Optimization Matters Now
Cloud infrastructure was originally sold on flexibility. Teams could provision resources quickly, scale on demand, and avoid heavy upfront capital expenditure. That value proposition still holds, but many companies now operate at a scale where cloud costs are one of the largest line items after payroll.
The issue is not only the size of the bill. It is the lack of predictability.
A product launch, analytics workload, AI experiment, logging spike, or inefficient query can create a material cost increase before anyone understands the cause. Finance teams see the bill after the fact. Engineering teams often see cost controls as constraints. Product teams may not know which features are expensive to run.
This creates a familiar pattern: leadership demands cost reduction, engineering reacts defensively, finance pushes for blunt cuts, and performance risk rises.
Common mistakes include cutting capacity before understanding utilization patterns, treating all workloads as equally important, optimizing compute while ignoring storage, data transfer, observability, and managed services, buying commitments before usage is stable, measuring infrastructure cost without linking it to product value, and making cost reduction a one-time project instead of an operating habit.
The goal is not to make cloud infrastructure cheap. The goal is to make it economically intentional.
1. Start With Workload Intent, Not the Invoice
A cloud bill shows where money went. It rarely explains whether that spending was justified.
Before making changes, classify workloads by business purpose and performance sensitivity. A customer-facing checkout service, a nightly analytics job, a development sandbox, and a machine learning experiment should not be governed by the same cost rules.
A useful classification should distinguish between revenue-critical production workloads, customer-facing but non-critical services, internal business applications, batch processing and analytics, development and test environments, and experimental or temporary workloads. Each of these categories has different expectations for availability, latency, scaling, and cost tolerance.
For example, a payment authorization service may justify higher redundancy and reserved capacity because performance degradation directly affects revenue. A reporting job that runs overnight may tolerate slower execution if it reduces compute cost by 40%. A staging environment may not need to run outside business hours.
This is where many cost programs fail. They try to optimize infrastructure in isolation, without asking what the workload is meant to achieve.
Cost reduction becomes safer when teams define the performance contract first. What latency is acceptable? What recovery time is required? What usage pattern is expected? What happens if the service slows down?
Without those answers, “optimization” becomes guesswork.

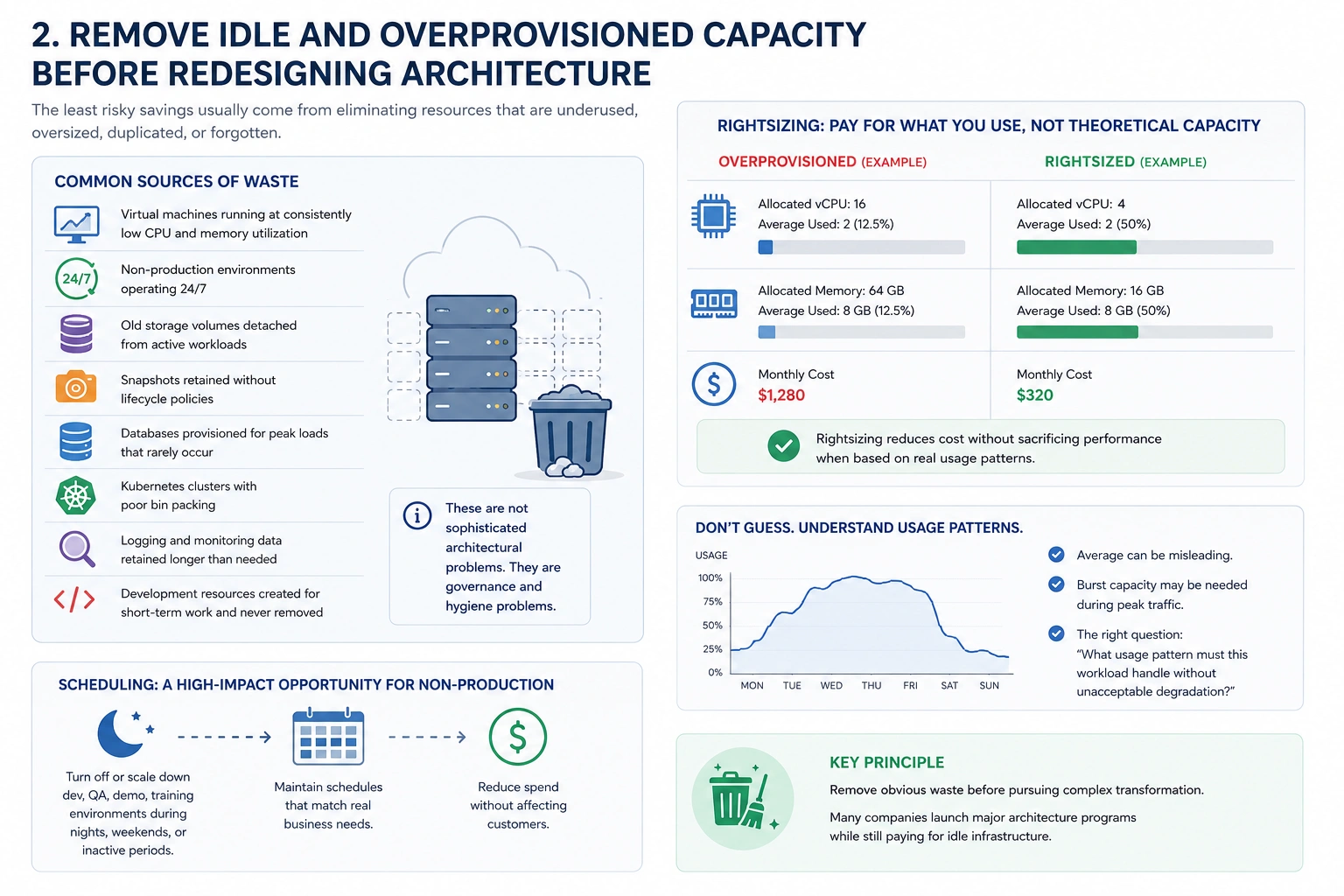
2. Remove Idle and Overprovisioned Capacity Before Redesigning Architecture
The least risky savings usually come from eliminating resources that are underused, oversized, duplicated, or forgotten.
In many environments, significant waste comes from basic operational drift. Virtual machines may run at consistently low CPU and memory utilization. Non-production environments may operate 24/7 even when no one uses them. Old storage volumes can remain detached from active workloads. Snapshots may be retained without lifecycle policies. Databases are often provisioned for peak loads that rarely occur. Kubernetes clusters may suffer from poor bin packing. Logging and monitoring data can be retained longer than needed. Development resources created for short-term work often become permanent by accident.
These are not sophisticated architectural problems. They are governance and hygiene problems.
Rightsizing is often the first serious lever. If an instance, container, database, or warehouse is consistently using a small fraction of its allocated resources, the organization is paying for theoretical capacity rather than actual demand.
However, rightsizing should not be done blindly. Average utilization can be misleading. A service may appear underused most of the day but require burst capacity during peak traffic. The right question is not only, “What is the average usage?” It is, “What usage pattern must this workload handle without unacceptable degradation?”
For non-production environments, scheduling is often an underrated opportunity. Development, QA, demo, and training environments may not need continuous uptime. Turning them off during nights, weekends, or inactive periods can reduce spend without affecting customers.
The key principle is simple: remove obvious waste before pursuing complex transformation. Many companies launch major architecture programs while still paying for idle infrastructure.
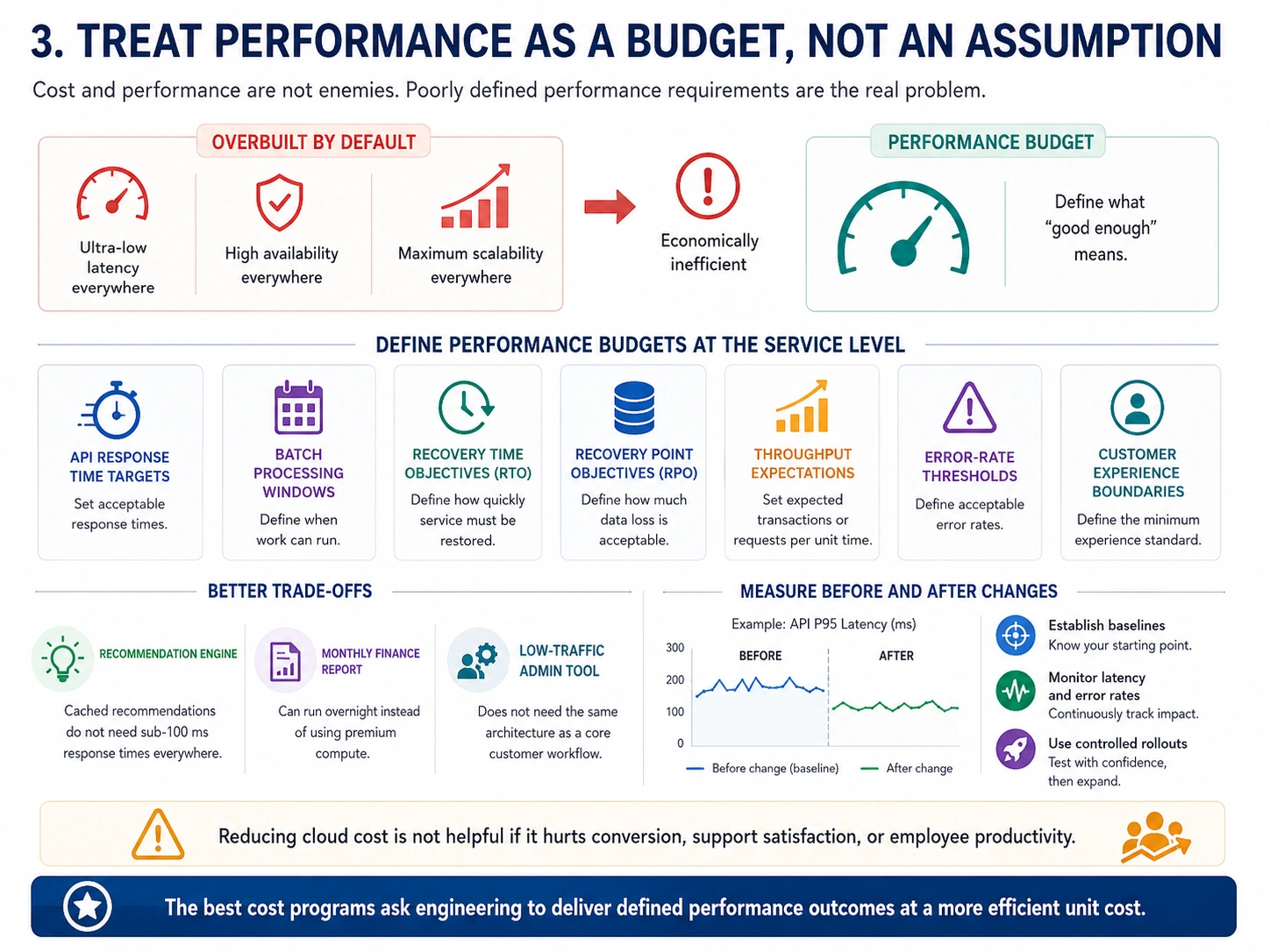
3. Treat Performance as a Budget, Not an Assumption
Cost and performance are not enemies. Poorly understood performance requirements are the real problem.
Many systems are overbuilt because nobody has defined what “good enough” means. Teams optimize for low latency everywhere, high availability everywhere, and maximum scalability everywhere. That sounds responsible, but it is usually economically inefficient.
A mature cloud cost strategy defines performance budgets at the service level. This means setting clear expectations for API response times, acceptable batch processing windows, recovery time objectives, recovery point objectives, throughput levels, error-rate thresholds, and customer experience boundaries.
Once these are clear, teams can make better trade-offs. A recommendation engine may not need sub-100 millisecond response times if recommendations are cached. A monthly finance report may not need premium compute if it can run overnight. A low-traffic admin tool may not require the same architecture as a core customer workflow.
This approach also helps prevent over-optimization. Reducing cloud cost by 10% is not useful if it increases page load times enough to reduce conversion, support satisfaction, or employee productivity.
Performance should be measured before and after cost changes. That means establishing baselines, monitoring latency and error rates, and using controlled rollouts rather than broad changes.
The best cost programs do not ask engineering to “spend less.” They ask engineering to deliver defined performance outcomes at a more efficient unit cost.
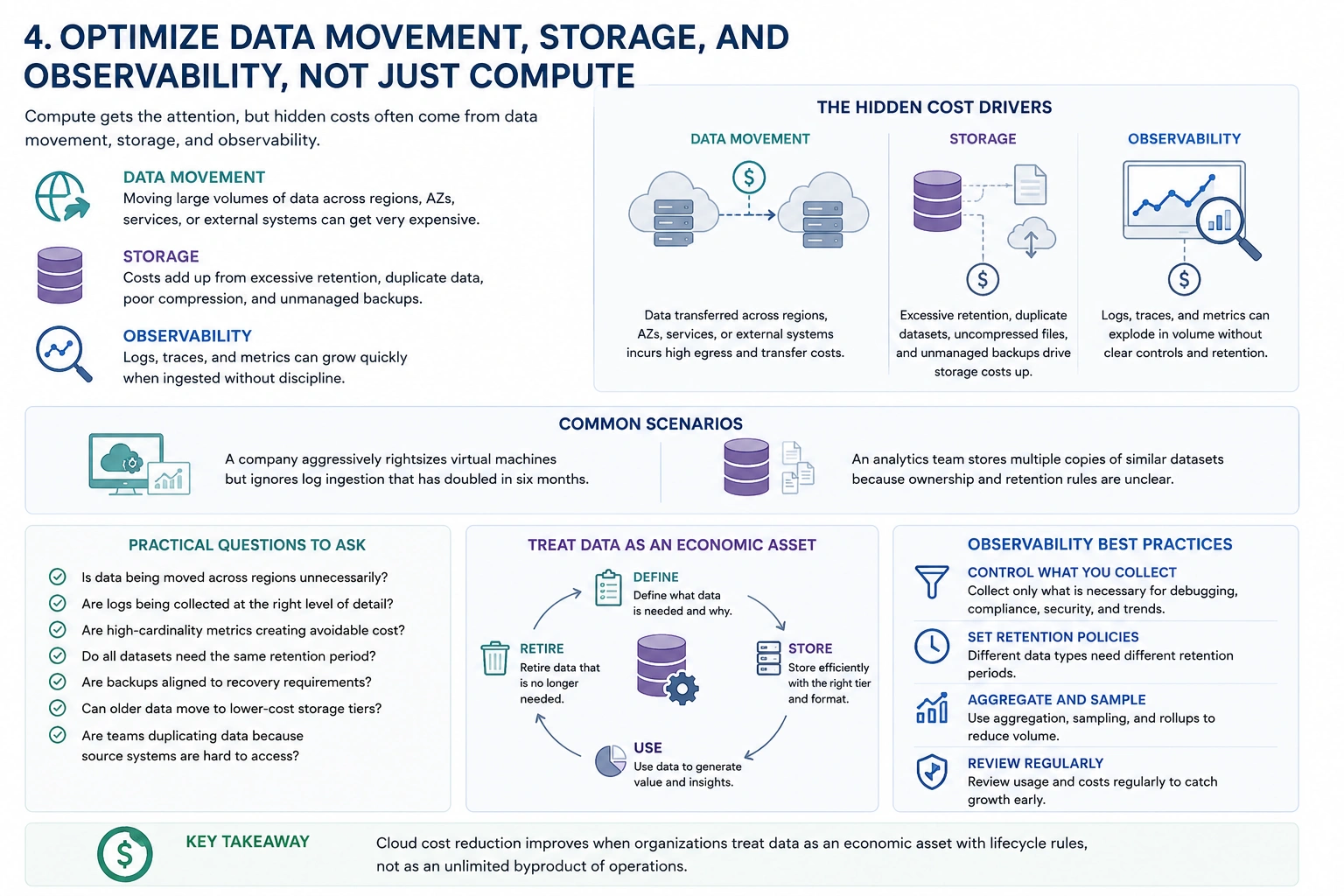
4. Optimize Data Movement, Storage, and Observability, Not Just Compute
Compute receives most of the attention because it is visible and easy to understand. But in many cloud environments, the hidden cost drivers sit elsewhere.
Data transfer can become expensive when architectures move large volumes of data across regions, availability zones, services, or external systems. Storage costs can accumulate through excessive retention, duplicated datasets, poorly compressed files, and unmanaged backups. Observability platforms can grow rapidly when logs, traces, and metrics are ingested without discipline.
A common scenario is a company that optimizes virtual machines aggressively while ignoring log ingestion that has doubled in six months. Another is an analytics team that stores multiple copies of similar datasets because ownership and retention rules are unclear.
Practical review should focus on whether data is being moved across regions unnecessarily, whether logs are collected at the right level of detail, whether high-cardinality metrics are creating avoidable cost, whether all datasets need the same retention period, whether backups are aligned to recovery requirements, whether older data can move to lower-cost storage tiers, and whether teams are duplicating data because the source systems are hard to access.
Cloud cost reduction often improves when organizations treat data as an economic asset with lifecycle rules, not as an unlimited byproduct of operations.
Observability deserves special attention. Logs and traces are essential for reliability, but collecting everything forever is rarely necessary. Teams should define what must be retained for debugging, compliance, security, and trend analysis. More data is not always better. Sometimes it simply makes systems more expensive and harder to reason about.
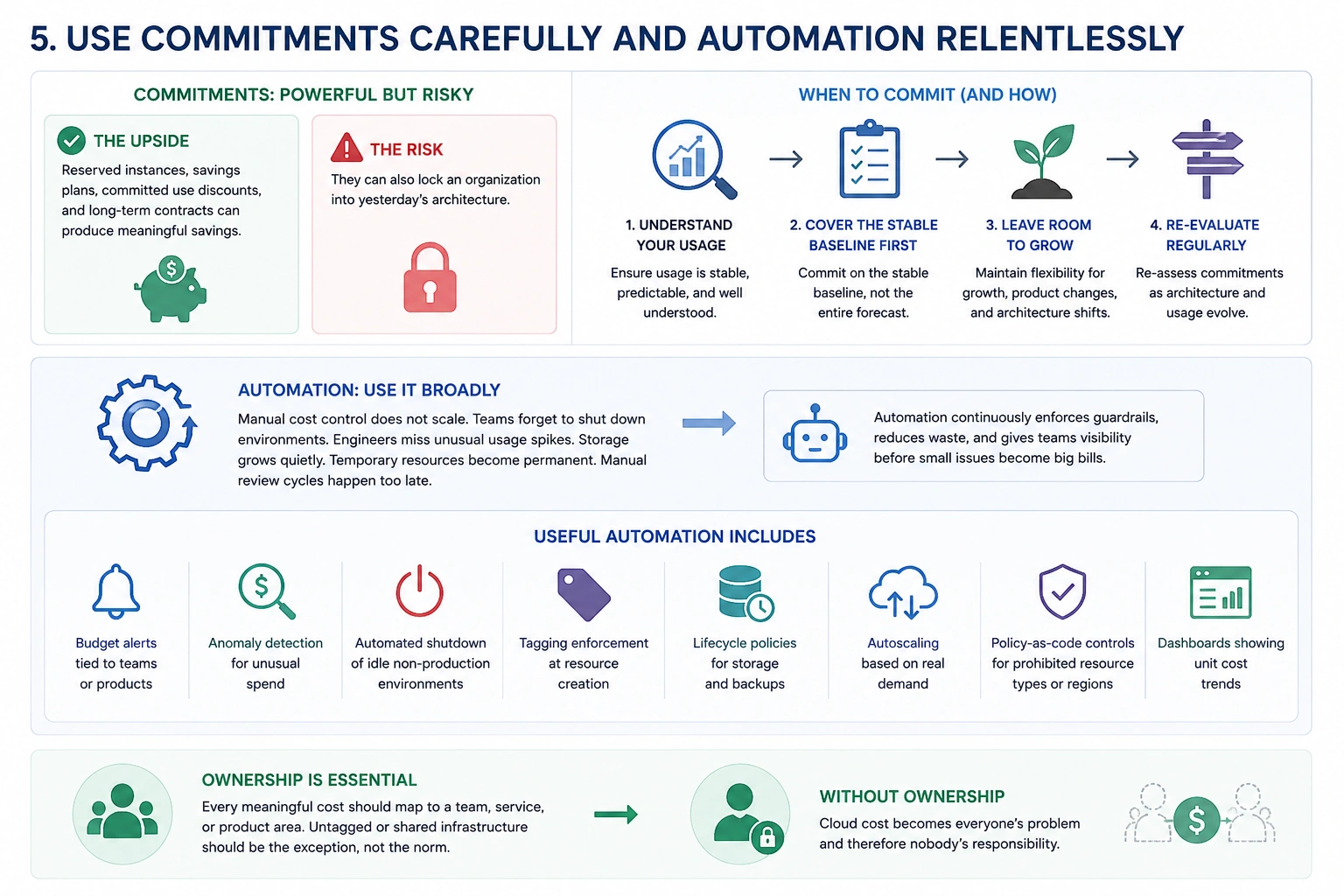
5. Use Commitments Carefully and Automation Relentlessly
Reserved instances, savings plans, committed use discounts, and long-term contracts can produce meaningful savings. They can also lock an organization into yesterday’s architecture.
Commitments work best when usage is stable, predictable, and well understood. They are risky when a company is still changing platforms, migrating workloads, experimenting with regions, or redesigning its product architecture.
A disciplined approach is to commit gradually. Cover the stable baseline first, not the entire forecast. Leave flexibility for growth, product changes, and architectural shifts.
Automation is different. It should be used broadly.
Manual cost control does not scale. Teams forget to shut down environments. Engineers miss unusual usage spikes. Storage grows quietly. Temporary resources become permanent. Manual review cycles happen too late.
Useful automation includes budget alerts tied to teams or products, anomaly detection for unusual spend, automated shutdown of idle non-production environments, tagging enforcement at resource creation, lifecycle policies for storage and backups, autoscaling based on real demand, policy-as-code controls for prohibited resource types or regions, and dashboards showing unit cost trends.
The most important part is ownership. Every meaningful cost should map to a team, service, or product area. Untagged or shared infrastructure should be the exception, not the norm.
Without ownership, cloud cost becomes everyone’s problem and therefore nobody’s responsibility.
Key Takeaways
Reducing cloud costs without breaking performance requires judgment, not just tooling.
The most practical principles are:
- Start with workload purpose and business criticality before making cuts.
- Remove idle, oversized, and forgotten resources before redesigning systems.
- Define performance budgets so teams know what must be protected.
- Look beyond compute to data transfer, storage, backups, and observability.
- Use cloud commitments only where usage is stable and predictable.
- Automate cost controls so savings do not depend on manual discipline.
- Assign ownership so teams understand the cost of the products and services they operate.
- Measure unit economics, such as cost per customer, transaction, report, or workload, not only total spend.
The deeper lesson is that cloud efficiency is not a one-time savings initiative. It is a management system.
Cost Efficiency Is an Architecture Choice
Cloud waste rarely appears all at once. It accumulates through small decisions: an oversized database, a forgotten test environment, excessive log retention, a duplicated dataset, a premium service used where a simpler one would work.
The same is true of cloud efficiency. It is built through repeated decisions that connect technical design to business value.
The strongest organizations do not frame cloud cost optimization as austerity. They frame it as architectural clarity. They know which workloads deserve premium performance, which can tolerate delay, which should scale dynamically, and which should not exist at all.
The question for leaders is not whether cloud costs can be reduced. In most organizations, they can.
The better question is: which costs are buying real business performance, and which are simply funding operational ambiguity?











