Most startups do not ignore disaster recovery because they are careless.
They ignore it because everything else feels more urgent.
Shipping features, acquiring customers, closing funding, hiring engineers, supporting early users, and proving market demand all seem more immediate than planning for a failure that may never happen. Disaster recovery often feels like something mature companies do after they have scale, compliance requirements, and dedicated infrastructure teams.
That assumption is risky.
For a startup, a major outage, data loss incident, cloud misconfiguration, failed deployment, or vendor disruption can be more damaging than it would be for a larger company. Established companies may have brand trust, operational buffers, and customer patience. Startups usually have less of all three.
Disaster recovery is not about creating enterprise-grade bureaucracy too early. It is about understanding which failures could seriously threaten the business and putting reasonable, testable safeguards in place before those failures become existential.
Why Disaster Recovery Matters Earlier Than Most Startups Think
Disaster recovery is often treated as a technical concern. Teams associate it with backups, failover, replication, infrastructure restoration, database recovery, and incident response.
Those elements matter. But the real issue is business continuity.
What happens if the production database becomes corrupted? What if a cloud region goes down? What if a deployment deletes customer files? What if a third-party authentication provider has an extended outage? What if ransomware affects internal systems? What if the only engineer who understands the infrastructure is unavailable during a critical incident?
For startups, the goal is not to prevent every possible failure. That is unrealistic.
The better question is which failures would materially damage customer trust, revenue, compliance posture, or the company’s ability to operate.
Many startups overestimate the resilience of modern cloud platforms and underestimate the fragility of their own operating model. Cloud providers may offer strong infrastructure reliability, but they do not automatically protect a company from poor access controls, accidental deletion, weak backup policies, bad deployments, undocumented recovery steps, or dependency concentration.
A cloud platform can be reliable while the startup built on top of it remains highly fragile.
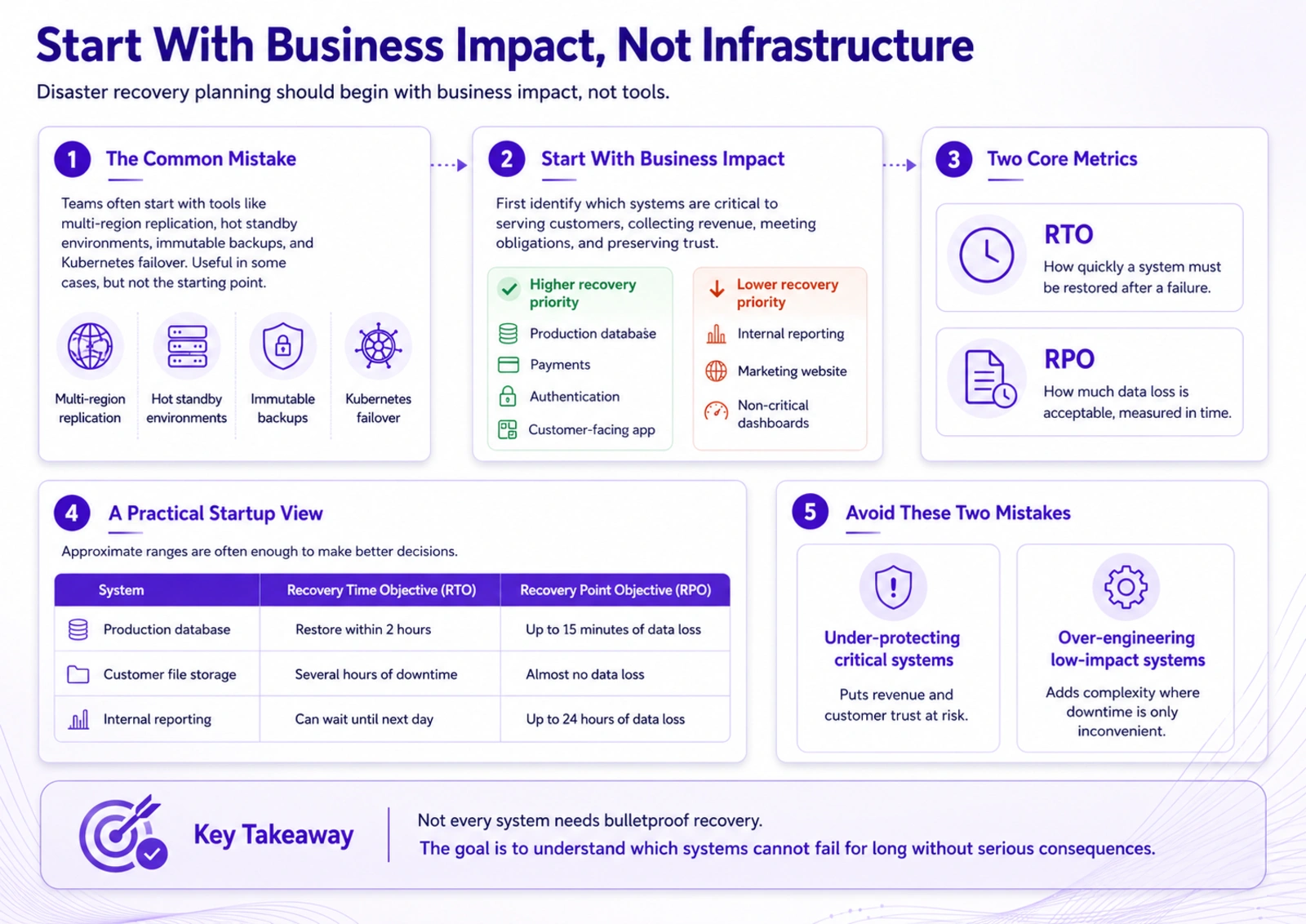
Start With Business Impact, Not Infrastructure
A common mistake is to begin disaster recovery planning with tools.
Teams often ask whether they need multi-region replication, hot standby environments, immutable backups, Kubernetes failover, or a more advanced cloud architecture. Those solutions may be useful in some cases, but they are not the starting point.
The starting point is business impact.
A startup should first identify which systems are critical to its ability to serve customers, collect revenue, meet obligations, and preserve trust. Not every system requires the same level of recovery.
An internal analytics dashboard can usually tolerate longer downtime. A payment system usually cannot. A customer-facing SaaS application may need faster recovery than a marketing website. A learning platform used for scheduled enterprise training sessions may have different recovery needs from a self-service product used asynchronously.
Two concepts are especially useful here: Recovery Time Objective and Recovery Point Objective.
Recovery Time Objective defines how quickly a system needs to be restored after a failure. Recovery Point Objective defines how much data loss is acceptable, usually measured in time.
A startup does not need perfect numbers at the beginning. Approximate ranges are often enough to make better decisions.
For example, the production database may need to be restored within two hours with no more than fifteen minutes of data loss. Customer file storage may tolerate several hours of downtime but almost no data loss. Internal reporting may be able to wait until the next day. A marketing website may be inconvenient to lose for a few hours, but it is rarely as business-critical as billing, authentication, or the core application.
This kind of mapping prevents two opposite mistakes.
The first mistake is under-protecting systems that are central to customer trust and revenue. The second is over-engineering resilience for systems where downtime would be annoying but not damaging.
The point is not to make every system bulletproof. The point is to understand which systems cannot fail for long without serious consequences.
 Backups Are Not a Recovery Strategy Unless They Are Tested
Backups Are Not a Recovery Strategy Unless They Are Tested
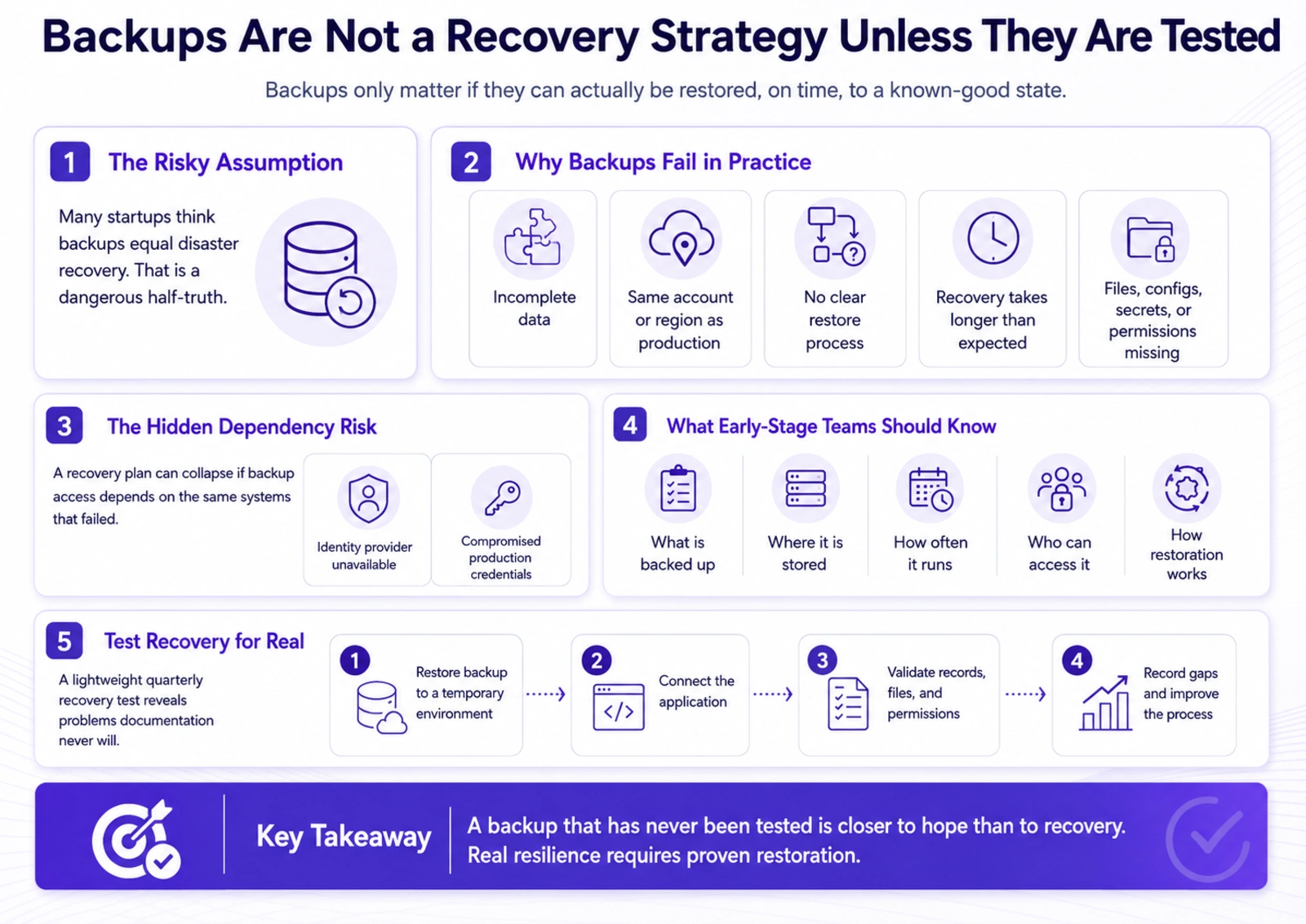
Many startups believe they have disaster recovery because they have backups.
That is a dangerous half-truth.
Backups are only useful if they can be restored reliably, within an acceptable time, and to a known-good state. A backup that has never been tested is closer to a hope than a recovery strategy.
In practice, backup problems are common. Sometimes backups exist but do not include all required data. Sometimes they are stored in the same cloud account or region as production. Sometimes no one knows how to restore them under pressure. Sometimes restoration takes much longer than expected. Sometimes database backups work, but file storage, configuration, secrets, or permissions are missing.
There is also a more subtle risk: backups can depend on the same systems that failed. If access to backups depends on an unavailable identity provider, or if backups are exposed to the same compromised credentials as production, the recovery plan may collapse when it is needed most.
For early-stage startups, the practical target should be simple. The team should know what is backed up, where it is stored, how often it runs, who can access it, and how restoration is performed.
A lightweight recovery test every quarter can reveal problems that documentation never will. For example, the team can restore a production database backup into a temporary environment, connect the application to it, and validate that critical records, files, and user permissions behave as expected.
This does not need to be a large exercise. But it does need to be real.
A recovery plan that has never been tested will likely fail in the exact conditions where it matters most: stress, urgency, incomplete information, and customer pressure.
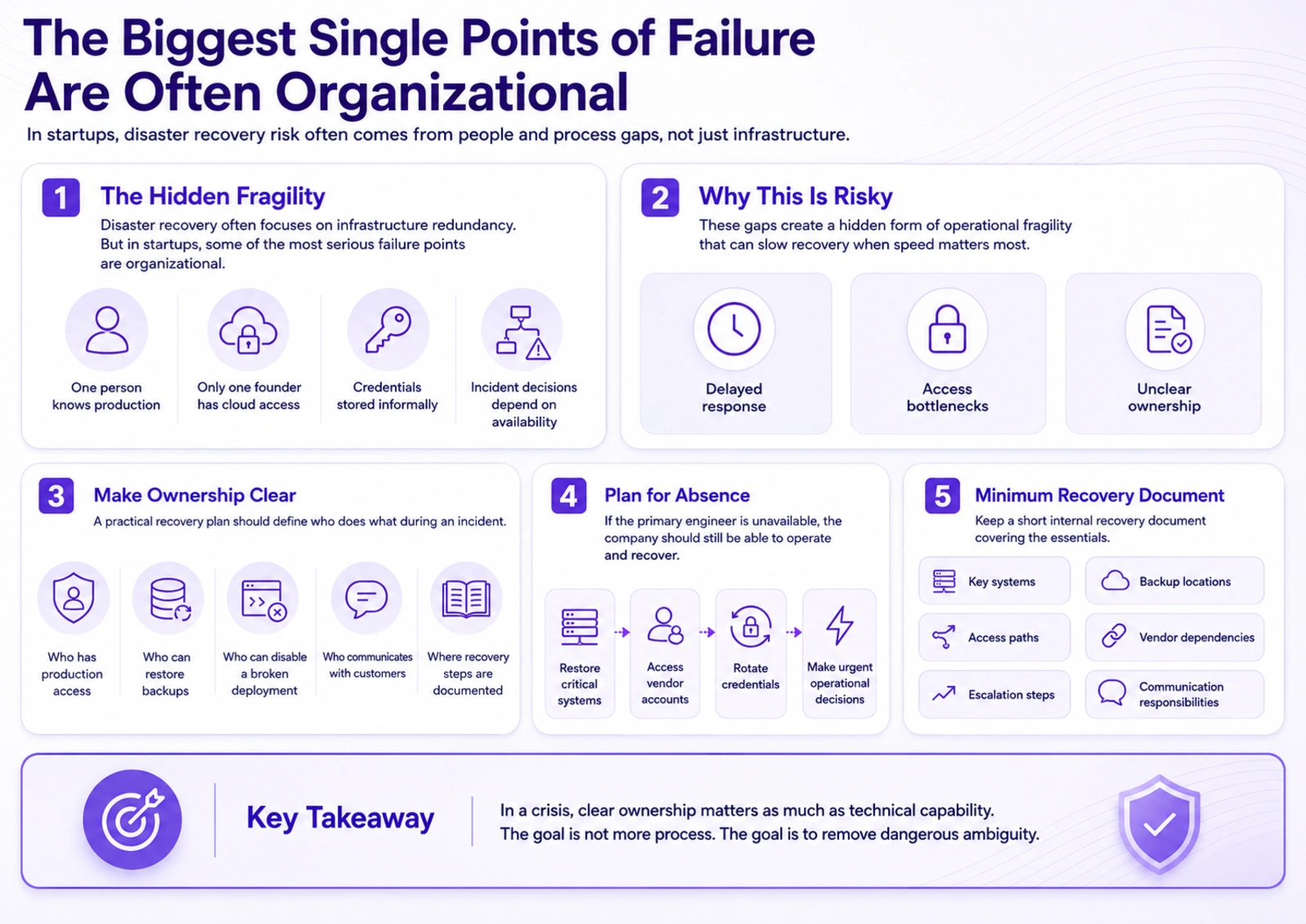
 The Biggest Single Points of Failure Are Often Organizational
The Biggest Single Points of Failure Are Often Organizational
Disaster recovery conversations often focus on infrastructure redundancy.
But in startups, some of the most serious single points of failure are people and processes.
A company may have automated backups, infrastructure-as-code, monitoring, and cloud redundancy, yet still be exposed because only one person knows how production is deployed. Or only one founder has access to the cloud account. Or credentials are stored informally. Or incident decisions depend on people being reachable in Slack at the right moment.
This creates a hidden form of operational fragility.
A practical startup disaster recovery plan should make ownership clear. The team should know who has access to production systems, who can restore backups, who can disable a broken deployment, who communicates with customers during an incident, and where recovery steps are documented.
It should also account for absence. If the primary engineer is unavailable, the company should still be able to restore critical systems, access vendor accounts, rotate credentials, and make urgent operational decisions.
The goal is not to create unnecessary process. The goal is to remove dangerous ambiguity.
At minimum, startups should maintain a short internal recovery document covering the most important systems, access paths, escalation steps, backup locations, vendor dependencies, and communication responsibilities.
In a crisis, clear ownership matters as much as technical capability.
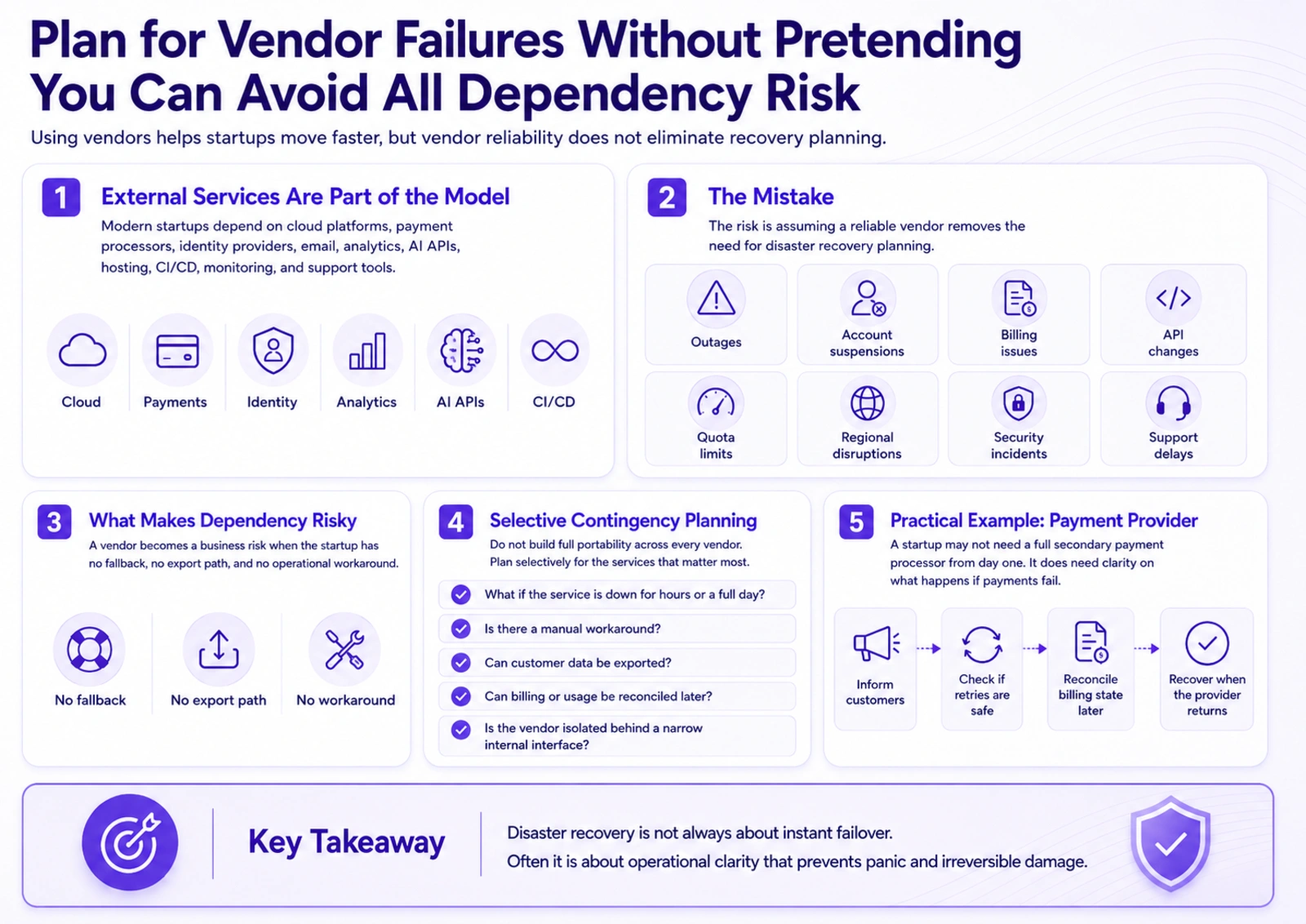
 Plan for Vendor Failures Without Pretending You Can Avoid All Dependency Risk
Plan for Vendor Failures Without Pretending You Can Avoid All Dependency Risk
Modern startups are built on external services. Cloud platforms, payment processors, identity providers, email systems, analytics tools, AI APIs, hosting platforms, CI/CD providers, monitoring tools, and customer support platforms are all part of the operating model.
This is not a weakness by itself. Using vendors is often the right decision. It allows startups to move faster and avoid building commodity infrastructure too early.
The mistake is assuming that vendor reliability eliminates the need for recovery planning.
Some vendor failures are temporary outages. Others are account suspensions, billing issues, API changes, quota limits, regional disruptions, security incidents, or support delays. Even a highly reliable provider can become a business risk if the startup has no fallback, no export path, and no operational workaround.
The answer is not to build full portability across every vendor. That would slow most startups down unnecessarily.
A better approach is selective contingency planning.
For critical vendors, the team should understand what happens if the service is unavailable for several hours or a full day. It should know whether there is a manual workaround, whether customer data can be exported, whether billing or usage state can be reconciled later, and whether the vendor is deeply embedded throughout the codebase or isolated behind a narrow internal interface.
For example, a startup may not need a full secondary payment processor from day one. But it should know what happens if payments fail, how customers are informed, whether retries are safe, and whether billing state can be corrected once the provider recovers.
Disaster recovery is not always about instant failover. Sometimes it is about having enough operational clarity to avoid panic and prevent irreversible damage.
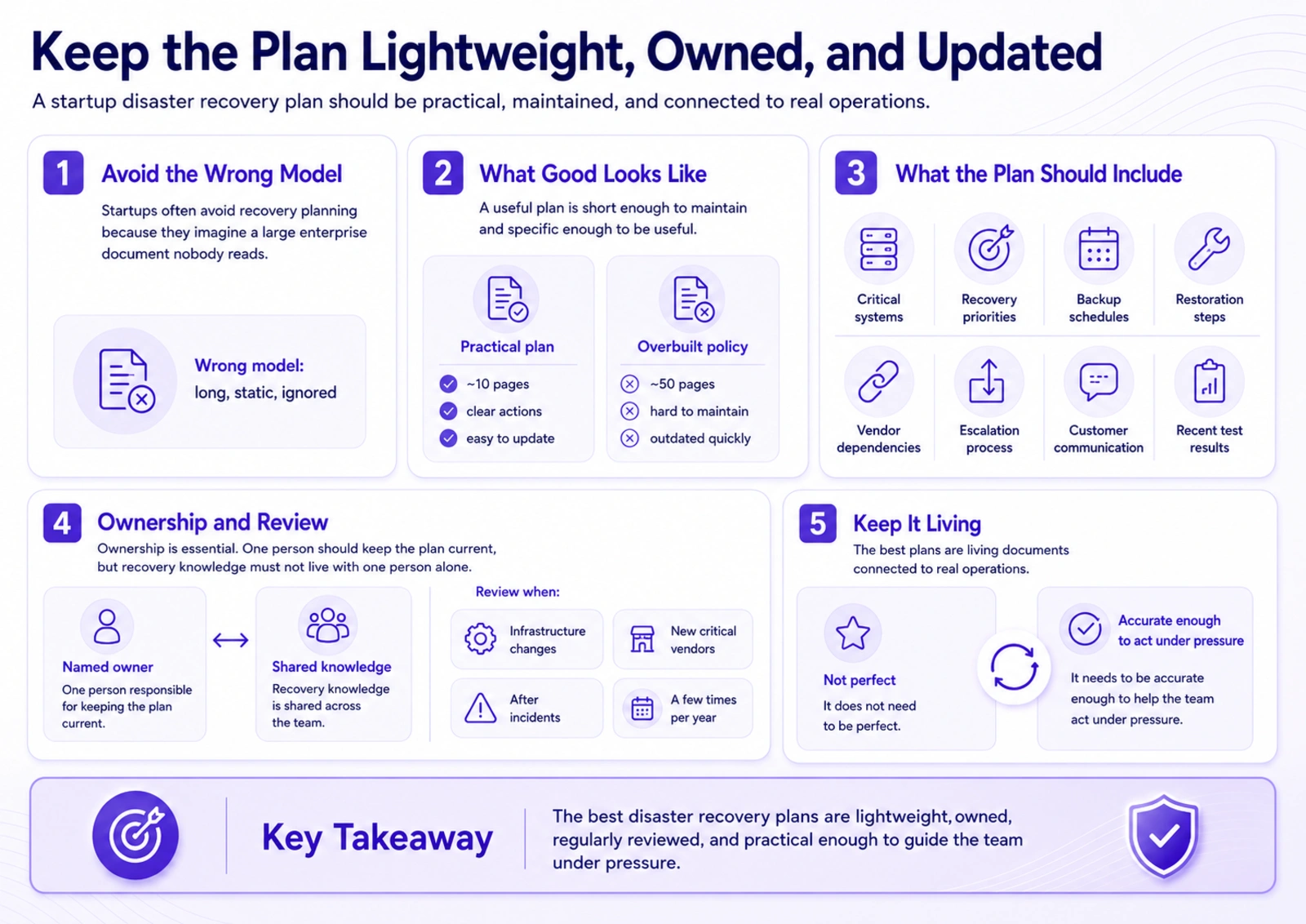
 Keep the Plan Lightweight, Owned, and Updated
Keep the Plan Lightweight, Owned, and Updated
A common reason startups avoid disaster recovery planning is that they imagine a large enterprise document that nobody reads.
That is the wrong model.
A startup disaster recovery plan should be short enough to maintain and specific enough to be useful. A practical ten-page document is better than a fifty-page policy that becomes outdated after two product releases.
The plan should clearly describe the company’s critical systems, recovery priorities, backup schedules, restoration steps, key vendor dependencies, escalation process, customer communication principles, and recent recovery test results.
Ownership is essential. If everyone owns disaster recovery, no one owns it.
One person should be responsible for keeping the plan current, but recovery knowledge should not live with one person alone. The plan should be reviewed when major infrastructure changes happen, when new critical vendors are introduced, after incidents, and at least a few times per year.
The best disaster recovery plans are living documents connected to real operations.
They do not need to be perfect. They need to be accurate enough to help the team act under pressure.
 Key Takeaways
Key Takeaways
Disaster recovery should start with business impact, not technology choices. Startups need to identify which systems matter most and define practical expectations for downtime and data loss.
Backups are necessary, but they are not sufficient. A backup strategy only becomes credible when restoration has been tested and the team understands how recovery works in practice.
The biggest risks are often organizational rather than purely technical. Missing documentation, unclear ownership, poor access control, and knowledge concentrated in one person can be as dangerous as infrastructure failure.
Vendor dependency is unavoidable, but unmanaged vendor dependency is risky. Startups should create contingency plans for the services that directly affect revenue, customer access, data, or core product functionality.
A lightweight plan is better than an impressive document nobody uses. The plan should be simple, current, owned, and tested through realistic recovery exercises.
Conclusion
Disaster recovery planning is not a sign that a startup is becoming slow, bureaucratic, or overly cautious.
Done well, it is the opposite. It gives the team confidence to move faster because the most serious failure scenarios are understood, documented, and partially rehearsed.
The real question is not whether a startup can prevent every incident. It cannot.
The question is whether the company can recover from predictable failures without losing customer trust, critical data, or operational control.
For early-stage companies, resilience does not need to mean enterprise complexity. It means knowing what matters, protecting it deliberately, and proving that recovery is possible before the business depends on it.